

起因
暑假捡了两张T10显卡,单卡有16GB的超大显存,还捡了一张X399主板,搭配线程撕裂者县城撕裂者2920X组了自己的工作站,在Windows下做一些AI视频修复和渲染的工作,16G的超大显存真的相当爽,做4K视频的补帧和渲染最爽的一集
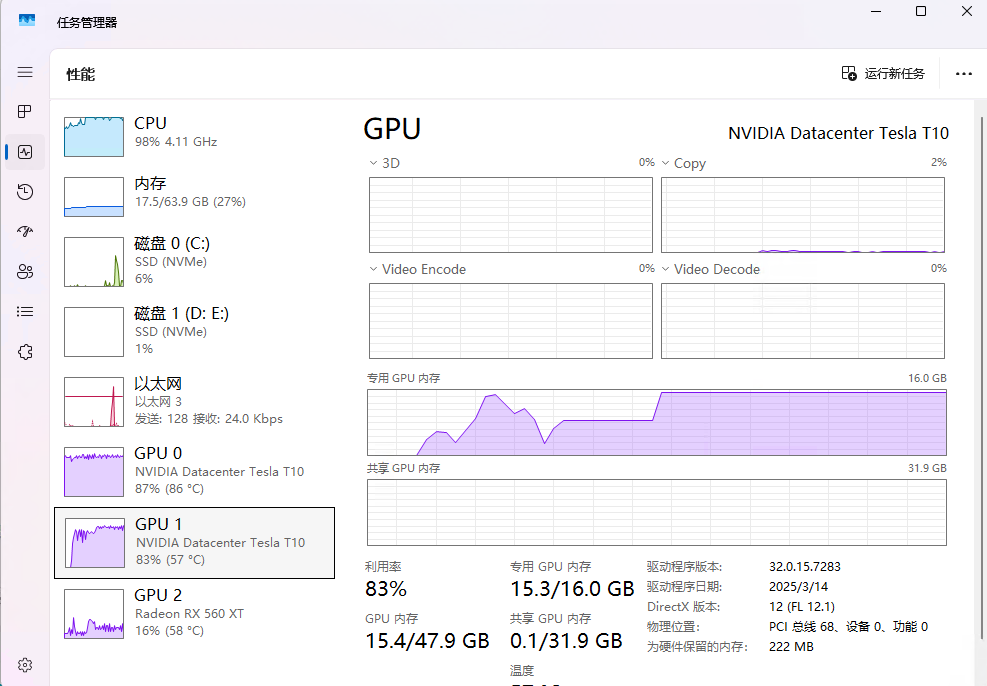
于是我欢天喜地的安装了Linux,想用这两张卡的超大显存玩一玩novel AI和Vllm,可是我在安装完nvidia闭源驱动后就发现了问题——我的另一张卡去哪里去了?
(base) fridayssheep@workstation:~$ nvidia-smi
Fri Oct 31 21:57:03 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.95.05 Driver Version: 580.95.05 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T10 Off | 00000000:0B:00.0 Off | Off |
| N/A 41C P8 11W / 150W | 5MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 1374 G /usr/lib/xorg/Xorg 4MiB |
+-----------------------------------------------------------------------------------------+我以为是Ubuntu的兼容问题,于是重新安装了Debian,发现问题并没有解决
于是我拆下了显卡,只安装了一张上去,诡异的事情发生了——两张T10单独拆下来只安装其中1张就能识别,但是另一张死活识别不了,但是Windows下是没有任何问题而且可以正常调用的,难不成另一张卡是Windows圣体,这辈子就认了跟Windows走?
解决问题
首先使用lspci | grep NVIDIA查看显卡物理连接有没有出现问题
(base) fridayssheep@workstation:~$ lspci | grep NVIDIA
0b:00.0 3D controller: NVIDIA Corporation TU102GL [Tesla T10 16GB / GRID RTX T10-2/T10-4/T10-8] (rev a1)
44:00.0 3D controller: NVIDIA Corporation TU102GL [Tesla T10 16GB / GRID RTX T10-2/T10-4/T10-8] (rev a1)两张T10显卡全部被识别到且连接正确,这就奇了怪了
再去使用dmesg查看并筛选有关nvidia的系统内核日志
fridayssheep@workstation:~$ sudo dmesg | grep -i nvidia
[ 9.159446] nvidia: loading out-of-tree module taints kernel.
[ 9.159460] nvidia: module license 'NVIDIA' taints kernel.
[ 9.159467] nvidia: module verification failed: signature and/or required key missing - tainting kernel
[ 9.159469] nvidia: module license taints kernel.
[ 9.806066] nvidia-nvlink: Nvlink Core is being initialized, major device number 235
[ 9.816154] nvidia 0000:0b:00.0: enabling device (0000 -> 0002)
[ 9.865243] NVRM: This PCI I/O region assigned to your NVIDIA device is invalid:
[ 9.865293] nvidia 0000:44:00.0: probe with driver nvidia failed with error -1
[ 9.866243] NVRM: The NVIDIA probe routine failed for 1 device(s).
[ 9.866248] NVRM: loading NVIDIA UNIX x86_64 Kernel Module 580.95.05 Tue Sep 23 10:11:16 UTC 2025
[ 9.929336] nvidia-modeset: Loading NVIDIA Kernel Mode Setting Driver for UNIX platforms 580.95.05 Tue Sep 23 09:41:17 UTC 2025
[ 9.949313] [drm] [nvidia-drm] [GPU ID 0x00000b00] Loading driver
[ 9.949444] [drm] Initialized nvidia-drm 0.0.0 for 0000:0b:00.0 on minor 1 [ 33.194292] nvidia_uvm: module uses symbols nvUvmInterfaceDisableAccessCntr from proprietary module nvidia, inheriting taint.这下终于发现了问题,没有识别的原因是这张卡的PCI 资源分配不足
[ 9.865243] NVRM: This PCI I/O region assigned to your NVIDIA device is invalid:
[ 9.865293] nvidia 0000:44:00.0: probe with driver nvidia failed with error -1
[ 9.866243] NVRM: The NVIDIA probe routine failed for 1 device(s).我们来逐步解析这三条日志
与之对应的,另一张Bus-ID为0000:0b:00.0卡正常启用并被 nvidia-drm 接管
[ 9.866248] NVRM: loading NVIDIA UNIX x86_64 Kernel Module 580.95.05 Tue Sep 23 10:11:16 UTC 2025
[ 9.929336] nvidia-modeset: Loading NVIDIA Kernel Mode Setting Driver for UNIX platforms 580.95.05 Tue Sep 23 09:41:17 UTC 2025
[ 9.949313] [drm] [nvidia-drm] [GPU ID 0x00000b00] Loading driver
[ 9.949444] [drm] Initialized nvidia-drm 0.0.0 for 0000:0b:00.0 on minor 1 [ 33.194292] nvidia_uvm: module uses symbols nvUvmInterfaceDisableAccessCntr from proprietary module nvidia, inheriting taint.我们将筛选范围扩大,剔除与 USB、网卡、声卡无关的内核日志,筛选dmesg的与BAR 分配失败、资源不足有关的日志
sudo dmesg | grep -Ei "NVRM|nvidia|BAR|resource|alloc|failed|error" | grep -v "usb"终于在输出的一大堆日志中找到了这几行
[ 0.369249] pci 0000:44:00.0: BAR 1 [mem size 0x400000000 64bit pref]: can't assign; no space
[ 0.369252] pci 0000:44:00.0: BAR 1 [mem size 0x400000000 64bit pref]: failed to assign
[ 0.369260] pci 0000:44:00.0: BAR 0 [mem size 0x01000000]: can't assign; no space
[ 0.369294] pci_bus 0000:40: Some PCI device resources are unassigned, try booting with pci=realloc这下破案了,第二块 NVIDIA GPU(44:00.0)BAR(Base Address Register)空间分配失败,也就是显存映射区没有成功分配到系统地址空间。
解决问题也很简单,日志的最后已经给出了解决方法:Some PCI device resources are unassigned, try booting with pci=realloc
我们去编辑/etc/default/grub
sudo vim /etc/default/grub按下i开始编辑,将GRUB_CMDLINE_LINUX_DEFAULT 项加入pci=realloc 即可
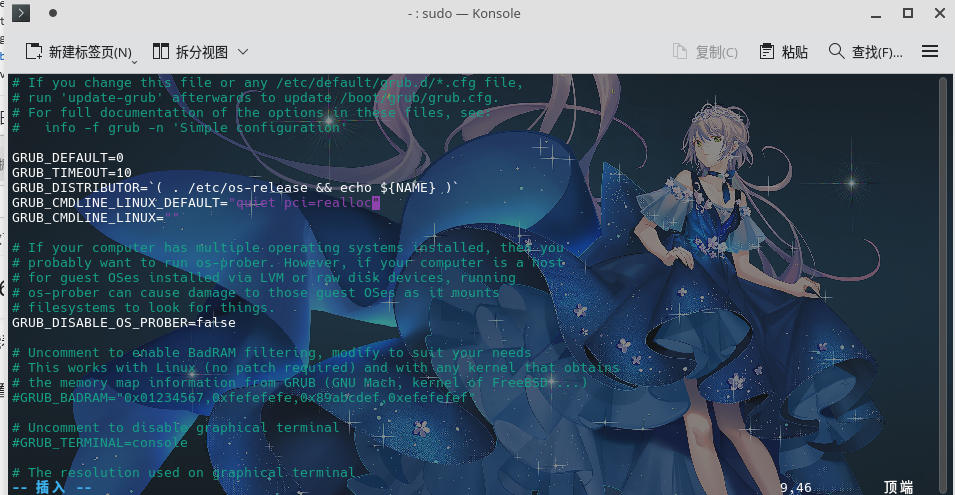
完成后,按下ESC 并输入:wq退出vim编辑器
别忘了使用update-grub更新grub
sudo update-grub重启系统后,第二张显卡终于出现了
(base) fridayssheep@workstation:~$ nvidia-smi
Sun Nov 2 15:57:18 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.95.05 Driver Version: 580.95.05 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T10 Off | 00000000:0B:00.0 Off | Off |
| N/A 41C P8 11W / 150W | 5MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 Tesla T10 Off | 00000000:44:00.0 Off | Off |
| N/A 40C P8 13W / 150W | 5MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 1374 G /usr/lib/xorg/Xorg 4MiB |
| 1 N/A N/A 1374 G /usr/lib/xorg/Xorg 4MiB |
+-----------------------------------------------------------------------------------------+后记
奇怪的是,理论上,我已经在主板BIOS设置里打开了Above 4G Decoding 来允许操作系统访问 4GB 以上的 PCI地址空间,这样的情况不应该出现
早期的PCI规范是诞生在 32 位 CPU 时代 的,那时候 CPU 的物理地址线只有 32 根。
所有 I/O 设备在“物理地址空间”中只能访问 0x00000000 ~ 0xFFFFFFFF
也就是 4GB(2³² 字节) 的范围。
每个 PCI 设备需要一块连续的物理地址空间,用于:
映射控制寄存器(BAR0)
映射显存窗口(BAR1)
映射 DMA 访问区
这些都要在系统物理地址空间中分配。
于是 BIOS 启动时必须做的第一件事是:枚举所有 PCI 设备,看看需要多大 MMIO 空间,然后在 0–4GB 范围内分配地址。
Above 4G Decoding 这个设置就是启用芯片组64bit兼容性硬件物理寻址能力
在希望很多设备并行使用时必须打开Above 4G Decoding,比如最早的多卡交火(SLI 不在内,因为他有专用通道,AMD 交火需要走芯片),机器学习需要并行算力,当然显卡挖矿必须要开,很多AMD 交火需要走芯片,为了提供多卡数据交互和切片,需要使用64bit 的寻址能力。
最后,我在level1techs找到了一篇对话,里面似乎指明了SR-IOV与 Above-4G 配合会造成分配行为异常,抱着好奇的心理,我尝试关闭了SR-IOV,得,TMD居然好了,在GRUB_CMDLINE_LINUX_DEFAULT 项pci=realloc不启用的时候也能识别到第二张卡了。。。
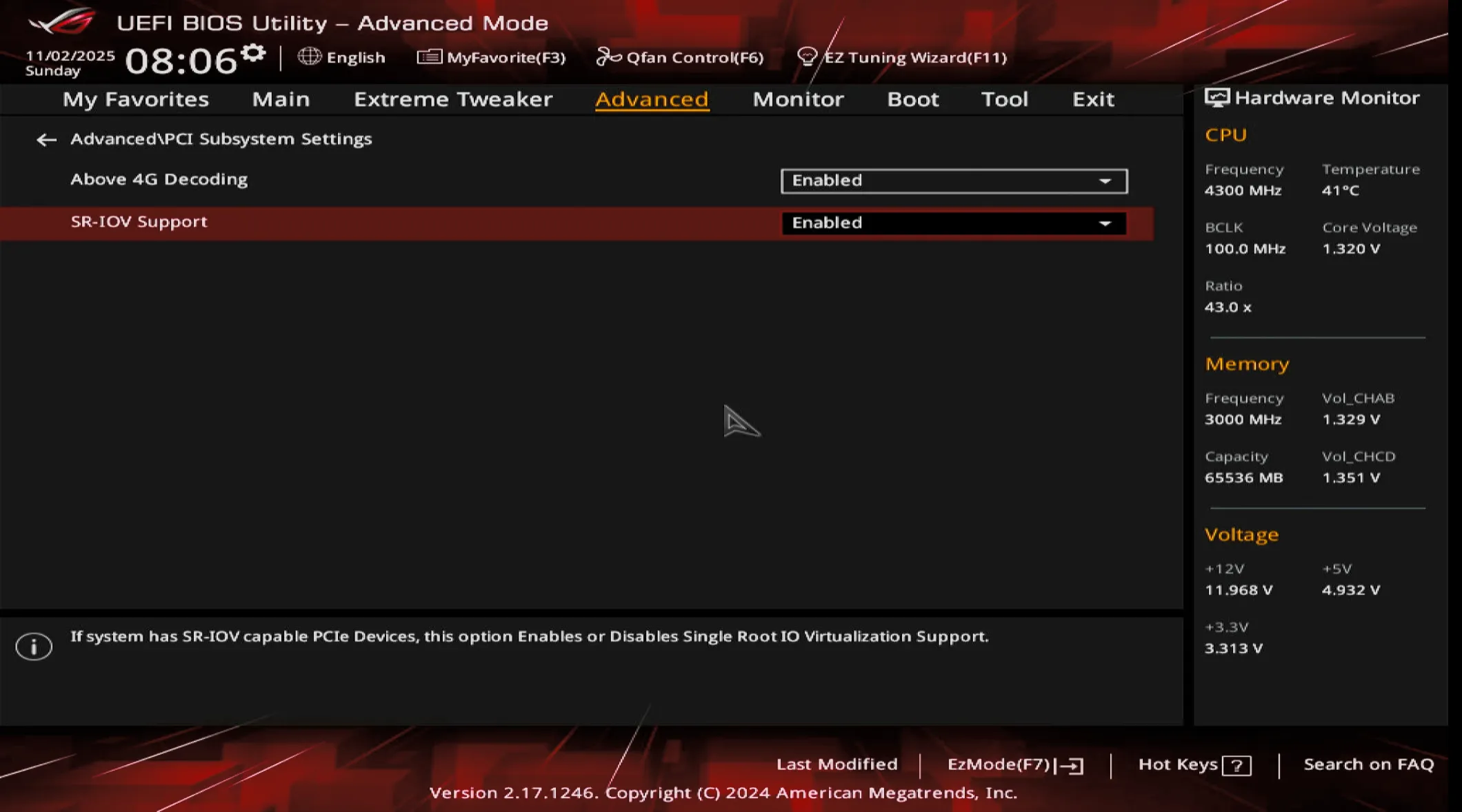
沟槽的华硕BIOS奇妙bug害我青春
记一次Linux/Ubuntu系统只能识别部分NVIDIA显卡问题
https://blog.fridayssheep.top/archives/fix_linux_can_only_detect_one_nvidia_card
评论